

Do you want to know what role Copyright plays in academia? What do you need to consider when it comes to publishing your work? What is secondary data and how does Copyright apply to it? Do you plan to work with international colleagues? If so, have you considered copyright in the international context? How can you avail copyright exemptions?
These are some of the main questions that were addressed during the two-day SSHOC workshop on Copyright Issues in Secondary Data Use organised by SSHOC on the 24th and 25th of January, 2022. The workshop was organised by the SSHOC project partner UK Data Service (UKDS), with a guest speaker from the Library and Culture Services, University of Essex. It consisted of several interactive sessions spread across two half days.
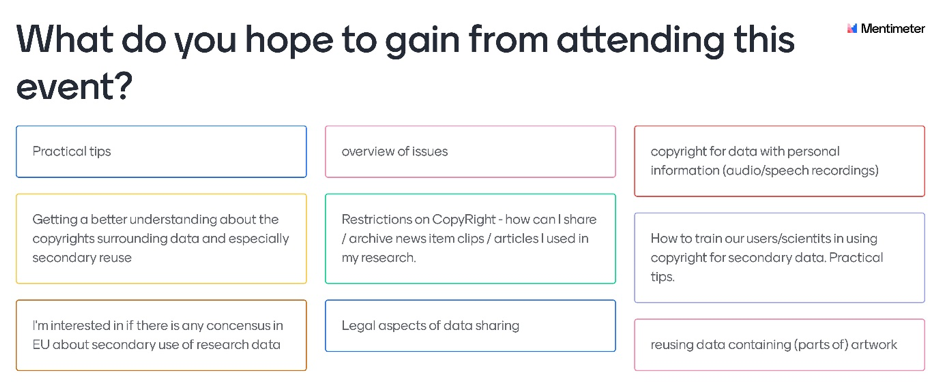
Cristina Magder, Data Collections Development Manager at UKDS, kicked off the workshop with an interactive introductory session which showed that the attendees were keen on learning about potential copyright issues in secondary data use and how these can be overcome. Some of the participants’ questions, which were addressed during the workshops, are shown below.
This introductory session was followed by a presentation made by Hina Zahid, Senior Research Data Officer at UKDS, who gave an overview of Copyright: its connection to Intellectual Property rights (IPR), its history and key terms in order to provide the context for the workshop. In general, IPRs are granted to creators and owners of works that are the result of human intellectual creativity. Copyright is thus only one type of IPRs and covers creative works such as books, music, etc. as opposed to other IPRs types covering, for example, patents, trademarks and registered designs.
It is a less known fact that the copyright, or rather the roots of copyright, date back to ancient Greece, but it was not until the 15th century, when the legal regulation of copyright was adopted due to a widespread use of the movable type printing press. Copyright as we know it today was implemented in the 1710s and is known as the Statute of Anne. Since then, due to international conventions, copyright acts across the world cover the same basic rights.
As explained by Hannah Pyman, Scholarly Communications Co-ordinator from University of Essex, creative work covered by Copyright can also be of several types. She introduced key concepts related to Copyright in the context of academic publishing and teaching, and covered several important copyright issues, such as the ones on the image below, which researchers need to consider when planning to publish their work, including manuscripts, in subscription based, hybrid or open access journals.

The workshop then moved to secondary data. The speaker, Maureen Haaker, Senior Qualitative Data and Training Officer at UKDS, explained what secondary data is, what are its sources and how to best discover secondary data. She has talked through some excellent examples of such data, for example microdata, census data, administrative data, business microdata etc. and concluded her talk pointing to a published paper that emphasizes how terms ‘primary’ and ‘secondary’ data should be used carefully.
Building on the previous session, Hina Zahid highlighted the most common copyright issues in secondary data use. She has covered key aspects such as who owns the copyright; university or an employee, university or student, research funder or researcher? What protection does copyright offers? What are database rights? And what happens when the copyright expires? Attention was also given to the best practices to deal with the so-called orphan works for which the rights holders cannot be identified.
The first day ended with an overview of some common questions regarding the Copyright as shown on the image below and a discussion about the main questions that need to be answered before re-using someone’s work, e.g. who the copyright holder of the datasets is, are you allowed to use the data and in what way; are you allowed to archive and publish the data in a data repository, etc.

Cristina Magder kicked off Day 2 of the workshop with welcome notes and a recap of the first day of the workshop, followed by an overview of the day with a focus on the benefits of sharing data outlined as shown on the image below:

The first section of the second of the workshop offered a brief overview of common data licences and addressed the topic of how copyright is inherently linked to licencing. The presentation included information on Open Licences such as Creative Commons (for an overview, see the image below), Open Data Commons and Government Licences to bespoke data licences used by national repositories and data archives. These different licenses all grant permission for anyone to make use of a certain work as long as the user follows the conditions of the specific license.
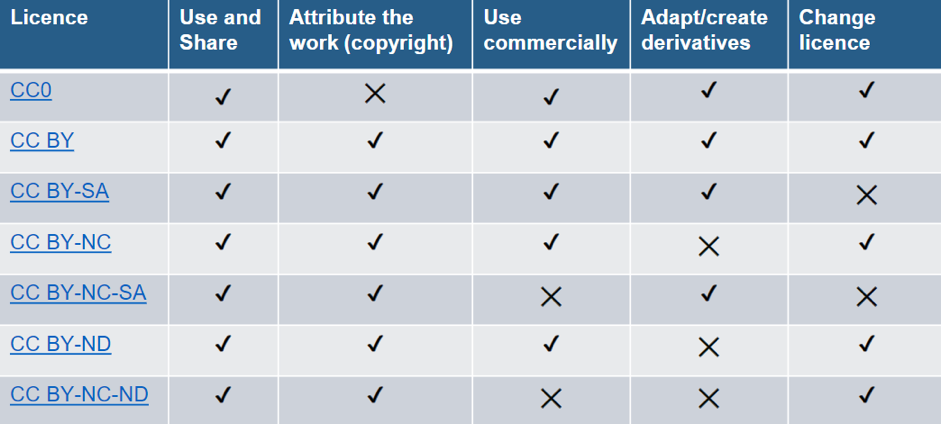
As data sharing is becoming more and more prevalent in the European research community, with some funders now mandating data sharing, the speaker also addressed the considerations when licencing data such as ownership (copyright does not equal ownership), contents of data (requirements linked to anonymization), type of users (commercial or non-commercial) and permission to share (sharing enable without or only with permission).
This led to an overview of copyright exceptions and limitations including the exception of ‘fair dealing’ and orphan works. The speaker underlined that copying the whole work would generally not be considered fair dealing, and while researchers are allowed to copy the whole work for their personal use, in most cases, they are not allowed to also share it. In addition, the speakers discussed possible reactions to potential infringements.
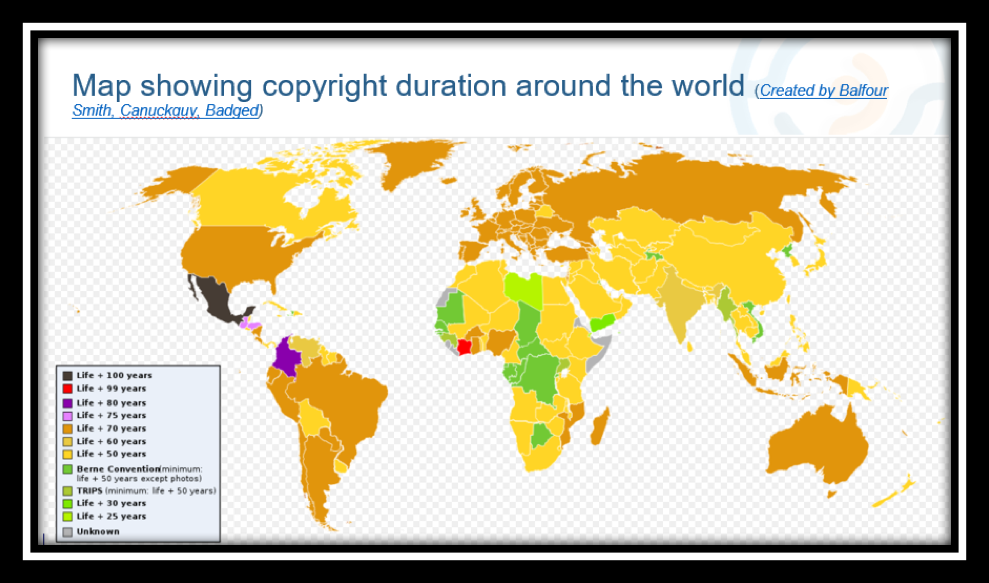
While there are some country specific variations in the Copyright, national Copyright laws are built on internationally accepted principles outlined in the ‘Berne Convention’ which has 179 member countries around the world. This treaty lays out several fundamental principles upon which all participating countries have agreed. The treaty defines minimum standards of protection regarding the types of works protected, duration of protection, scope of exceptions, limitations and principles such as “national treatment” and “automatic protection”.
Finally, Hina Zahid talked about Copyright and social media data. She discussed how the social media data is acquired and what are the copyright implications in using the data from these platforms, especially when it comes to data sharing and archiving for future use. Content on social media is protected by copyright in the same way as books and journals but by agreeing to post works on the site, users sign an agreement that gives the site a licence to use the work freely for a variety of purposes. Therefore, researchers using data from social media must abide by the terms and conditions of the platforms or API developers.
If you would like to get more from this information packed workshop, we invite you to take the time and watch the workshop recordings (Day 1, Day 2) and check the presentations (Day 1, Day 2). In particular, do not miss the final presentation of Day 2 (p. 55), where you will find a list of resources that can be useful in the context of copyright as well as some case studies about overcoming copyright issues in practice.
{kind=link}